Working memory is the small, fast, capacity-limited cognitive workspace the brain runs every focus task through. It is the reason you can hold a phone number long enough to dial it, lose your train of thought when a notification fires, calculate a tip in your head, or follow a sentence whose subject is at one end and verb at the other. It is also the cognitive construct with the deepest research base in the focus literature: the Baddeley multi-component model has held up across fifty years of replication, the Miller 7±2 vs Cowan 4±1 capacity argument is settled in the literature even if the popular press still cites Miller, and the link between working memory and ADHD is so strong that Russell Barkley has argued ADHD is fundamentally a working memory deficit rather than an attention deficit.
This piece is the cognitive-science version of working memory: what it is, what it is not, the four-component model Baddeley built and Cowan extended, the capacity limit that is closer to four chunks than seven, the digit-span and n-back tests that measure it, the ADHD link and the Barkley reframe, and the controversial question of whether working memory can be trained (with the short answer being "the test scores go up, the real-world transfer mostly does not"). Tomatoes is a focus tool built around the audio side of working memory, the music and binaural channel that occupies the phonological loop in a way that supports rather than competes with the task. The app is a one-time $39 with no subscription. The rest of this article is the science of what working memory is doing while you use it.
What Working Memory Actually Is
Working memory is the cognitive system that temporarily holds and manipulates the information you are currently using. The "currently using" part is the key distinction. Long-term memory is the warehouse: semantic facts, procedural skills, episodic experiences, available to be retrieved. Sensory memory is the eight-hundred-millisecond echo of what you just heard or saw, gone almost as quickly as it arrived. Working memory is the bench in the middle. It holds the few items you are actively thinking with right now, and it does so for seconds to tens of seconds without rehearsal, or longer if you rehearse.
Three properties define working memory and separate it from the surrounding memory systems:
It is active, not passive. Items in working memory are being manipulated, compared, integrated, or rehearsed. The classic distinction is between short-term memory as a passive store and working memory as the active workspace; Baddeley collapsed the two into a single working-memory framework in 1974 by giving the workspace a controller, the central executive, that does the active part.
It is severely capacity-limited. Four items, plus or minus one, is the well-replicated chunk-controlled estimate from Cowan (2001). Miller's seven plus or minus two (1956) is the inflated estimate that includes rehearsal and chunking strategies; when you control for those, the underlying capacity is closer to four. The bottleneck is small enough that working memory is the limiting reagent of most complex cognition.
It is duration-limited without rehearsal. Items decay from working memory in seconds unless they are refreshed. Refreshing happens either through silent rehearsal (the phonological loop saying the items to itself) or through attentional focus (a controlled attentional refresh, in Cowan's terminology). Distract the rehearsal and the items are lost.
Working memory is not short-term memory in the colloquial sense (a few minutes' recall). Short-term memory in the popular sense maps loosely onto a mix of the active workspace plus very recent long-term encoding. Working memory in the technical sense is the four-component model that follows.
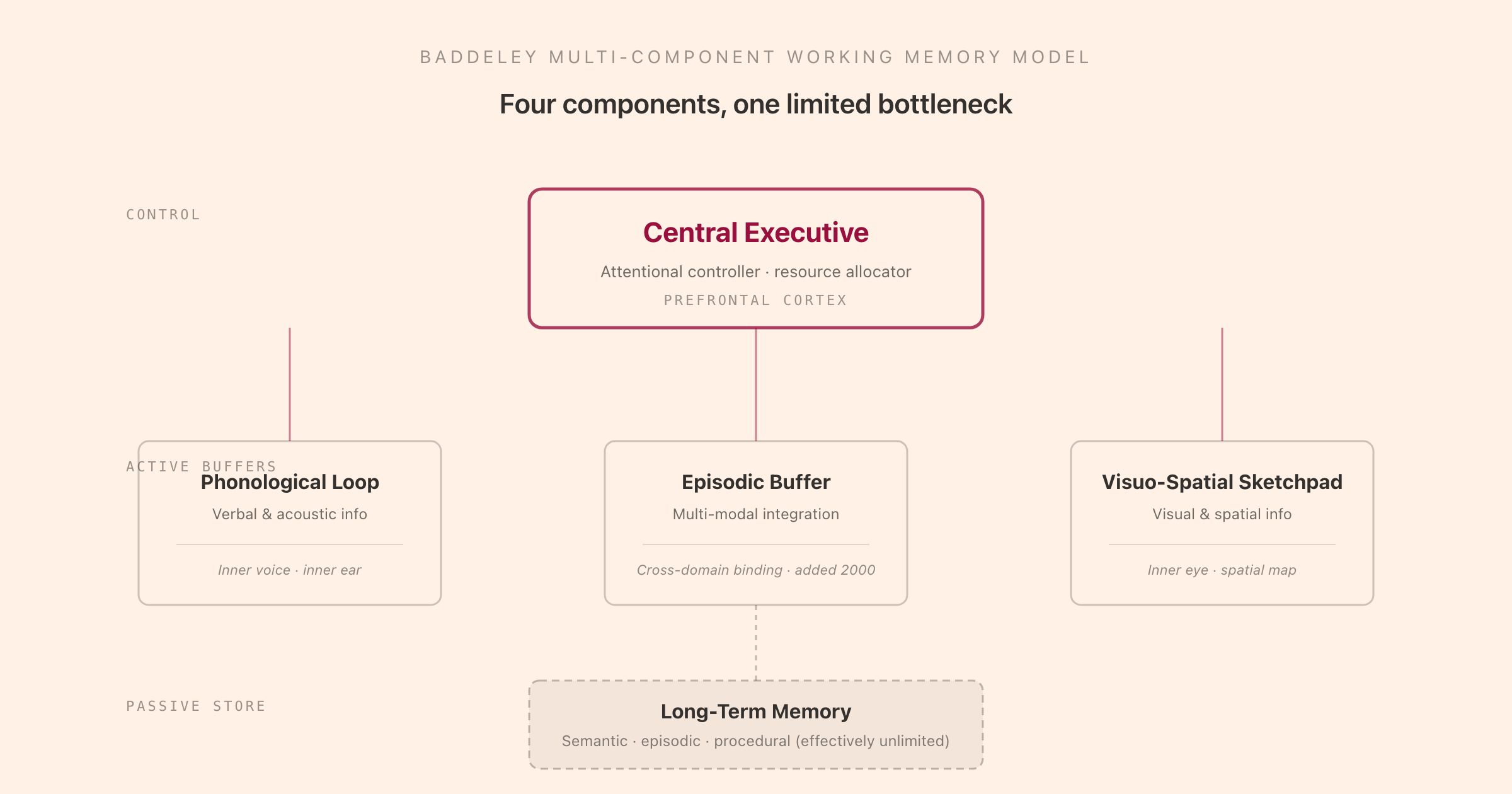
The Baddeley Model: Four Components, One Bottleneck
Alan Baddeley and Graham Hitch proposed the multi-component working memory model in 1974, then Baddeley extended it in 2000 with the addition of a fourth component, the episodic buffer. The model has four interacting parts, each with a specific job, neuroanatomy, and failure mode.
The central executive. The attentional controller. The central executive does not store information; it directs it. It decides which inputs the active buffers should hold, allocates capacity between them, suppresses irrelevant inputs, switches between subtasks, and reaches back into long-term memory to pull in relevant context. The neural substrate is broadly the prefrontal cortex, particularly the dorsolateral prefrontal cortex. The central executive is the bottleneck of effortful cognition. When you "lose focus," what fails is almost always central-executive control, not buffer capacity.
The phonological loop. The active buffer for verbal and acoustic information. It has two subcomponents: a phonological store that holds about two seconds of acoustic information, and an articulatory rehearsal mechanism (subvocal speech) that refreshes the store by silently repeating the items. The phonological loop is why you can hold a phone number by saying it to yourself, why concurrent verbal load (counting backwards) collapses your ability to memorise a list of words, and why the word-length effect exists (shorter words are easier to remember than longer ones because they fit more rehearsals per two-second window). The neural substrate is the left temporo-parietal cortex (store) plus Broca's area (rehearsal).
The visuo-spatial sketchpad. The active buffer for visual and spatial information. The "inner eye" that lets you mentally rotate a shape, hold a mental map of a room, or recall the shape of a fridge magnet without saying any words. The neural substrate is the right parieto-occipital cortex with some prefrontal involvement. The visuo-spatial sketchpad is independent of the phonological loop: holding a verbal list while doing a spatial task draws on separate resources, which is why the classic dual-task paradigm shows interference within a modality but tolerance across modalities.
The episodic buffer. Added by Baddeley in 2000 to account for findings the original three-component model could not explain (such as the ability to bind verbal and visual information into a unified percept, or the ability to recall chunks of information that exceed the phonological loop's capacity by drawing on long-term semantic structure). The episodic buffer is a limited-capacity store that holds multi-modal representations and binds them together. It interfaces with long-term memory more directly than the slave buffers do.
The model's clinical and experimental utility is high. Selective brain lesions impair specific components (a left temporo-parietal lesion produces a pure phonological-loop deficit while leaving visuo-spatial working memory intact). Dual-task paradigms produce the dissociation pattern the model predicts. Imaging studies show the predicted lateralisation. The model is not the only model in the literature (Cowan's embedded-process model, Engle's executive-attention model, and the more recent neural-network state-based models all compete with it), but it is the most cited and the most useful as a teaching frame.
The Capacity Limit: Miller 7±2 vs Cowan 4±1
The popular version of the working memory capacity limit is George Miller's 1956 paper, "The Magical Number Seven, Plus or Minus Two," and it has been the most widely cited claim in cognitive psychology for sixty years. Miller's argument was that the immediate memory span across modalities, after collapsing across rehearsal and chunking, sits in the range of about seven items. This is the number quoted in textbooks, design guidelines (the "seven items per menu" rule), and the popular press to this day.
The problem with the Miller estimate is that the seven figure includes rehearsal and chunking. When you read a list of seven digits and immediately repeat them, you are rehearsing in the phonological loop and you may be chunking the digits into smaller groups (the area code, the prefix, the suffix). What you are reporting is not the raw capacity of working memory; it is the inflated capacity once the rehearsal-and-chunking machinery has had time to work.
Nelson Cowan addressed this in a 2001 paper, "The Magical Number 4 in Short-Term Memory: A Reconsideration of Mental Storage Capacity." Cowan reviewed paradigms that prevent rehearsal and chunking (visual change-detection arrays, articulatory suppression that blocks the phonological loop, attention-divided dual tasks) and found a consistent underlying capacity of approximately four chunks. The four-chunk limit has been replicated repeatedly across the last twenty-five years and is now the consensus estimate in the cognitive psychology literature.
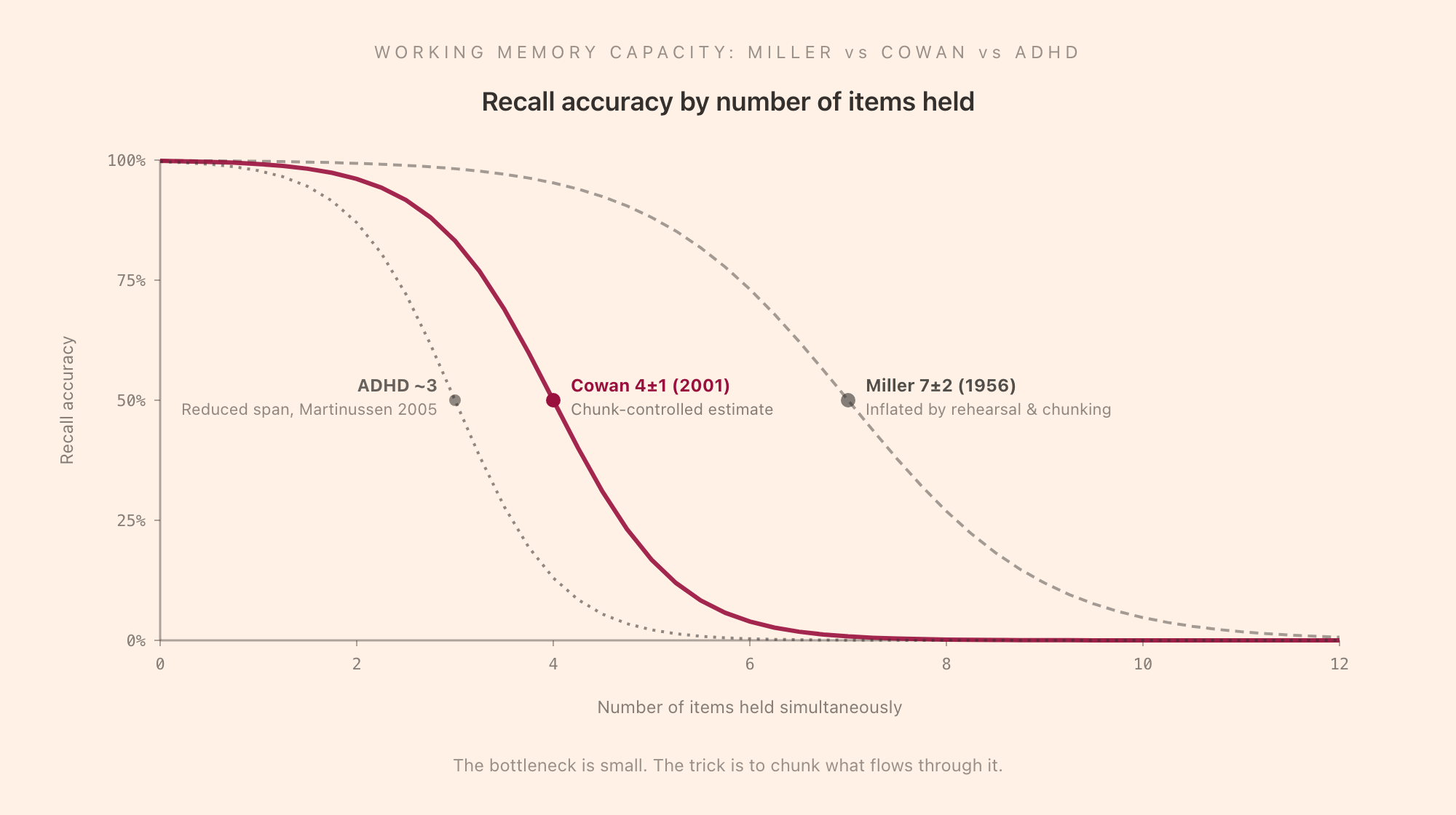
The practical implication is that working memory is much smaller than the popular literature suggests. The trick is not to expand the bottleneck (it does not expand) but to make the chunks denser. A chunk is whatever a single coherent unit is to the person doing the remembering. To a chess grandmaster, a board position is one chunk; to a novice, it is twenty-five chunks. Chunking is the long-term-memory side of the bottleneck: dense long-term knowledge produces denser chunks, which lets more information flow through the four-slot gate. This is also why expertise looks like enhanced working memory but is not: the storage limit is the same; the encoding density is different.
The 4±1 figure is the visuo-spatial and chunk-controlled verbal estimate. For purely articulatory phonological-loop tasks (immediate digit span without rehearsal blocking), the figure is closer to 5-7 because the phonological loop adds capacity by rehearsing the contents of a smaller central store. The point is that the central capacity is small; the loop adds on top of it.
How Working Memory Is Measured
Three tests dominate the experimental working-memory literature.
The digit span task. The classic measure. The participant hears a list of digits and immediately repeats them in order; the list lengthens until the participant fails. Forward digit span (repeat in order) probes the phonological loop. Backward digit span (repeat in reverse order) requires the central executive to manipulate the contents while holding them, and is the more commonly used working-memory measure. Backward digit span correlates with fluid intelligence, reading comprehension, and academic achievement. Healthy adults score around 7 forward / 5 backward; ADHD adults score about one item lower on backward (Martinussen et al., 2005, meta-analysis).
The n-back task. A stream of stimuli (letters, locations, sounds) is presented one at a time, and the participant indicates when the current stimulus matches the one n positions back. 2-back is moderately hard; 3-back is genuinely demanding. The n-back is the workhorse of the working-memory-training literature because it scales smoothly, can be made adaptive (the difficulty adjusts to keep accuracy near 70%), and is sensitive to individual differences. It has been criticised for measuring not pure capacity but the combination of capacity, attentional control, and interference resolution.
The complex span tasks. Operation span (do a maths problem, then remember a word, alternating, then recall all the words), reading span (read a sentence, then remember the last word, alternating), and counting span (count the dots, then remember the count, alternating). The complex span tasks add a processing load to the storage requirement and are the strongest predictors of fluid intelligence and academic achievement in the working-memory literature. They are messier to administer but the gold standard for measuring "useful" working memory rather than pure storage.
A quick informal estimate of your own backward digit span: have someone read you a six-digit number and ask you to repeat it in reverse. If you can do six, your backward span is around six. Most adults sit between five and seven.
Working Memory and ADHD
The link between working memory and ADHD is one of the strongest in cognitive psychiatry. Martinussen and colleagues (2005) meta-analysed 26 studies of working memory in ADHD children and found large, consistent deficits in both verbal and visuo-spatial working memory, with the visuo-spatial deficit being slightly larger. Alloway and colleagues (2010) found that working memory capacity at age 5 predicted academic achievement at age 11 more strongly than IQ did, and the effect held in both ADHD and non-ADHD samples. Kasper, Alderson, and Hudec (2012) meta-analysed adult ADHD and found the same pattern.
Russell Barkley's reframe goes further. Barkley has argued for two decades that what we call ADHD is fundamentally a deficit of executive function, with working memory and behavioural inhibition as the two central impairments, and that the attention deficit is downstream of the working memory deficit rather than the other way around. The argument: if working memory is the workspace where future-oriented goals are held against present distractors, a working memory deficit means future goals fade faster than they would otherwise, and behaviour defaults to whatever the most salient present stimulus is. That is the phenomenology of ADHD. Time blindness, the characteristic ADHD inability to hold a deadline in working contact with the present moment, falls out of the same deficit.
Whether ADHD is "really" a working memory disorder or "really" an attention disorder is a definitional argument; the practical implication is the same. Working memory load makes ADHD symptoms worse, environmental scaffolding that offloads working memory (lists, timers, sticky notes, calendar reminders, the visible deadline) makes them better, and the strongest non-pharmacological interventions for ADHD focus heavily on external working-memory scaffolds. The audio side of focus tools (consistent, non-distracting background music, binaural beats, brown noise) does some of this scaffolding work by occupying the phonological loop with a steady channel that supports rather than competes with the task. The ADHD focus music piece is the longer version of that argument.
Can Working Memory Be Trained?
The most contested question in the practical working-memory literature. The optimistic view, dominant in the early 2000s, was that targeted training (most famously the Cogmed n-back program) could increase working memory capacity, and that the gains would transfer to fluid intelligence, academic achievement, and ADHD symptom reduction. Jaeggi and colleagues (2008) published an influential paper claiming that intensive n-back training increased fluid intelligence in healthy adults.
The pessimistic view, which is now the consensus, came from the meta-analyses of the 2010s. Melby-Lervåg and Hulme (2013) meta-analysed 23 working-memory-training studies in children and adults and found that training produced reliable improvements on tasks closely resembling the training task ("near transfer") but no reliable improvement on dissimilar tasks ("far transfer") and no reliable improvement on real-world outcomes such as academic achievement or reasoning. Simons and colleagues (2016) reviewed the brain-training industry's claims more broadly and reached the same conclusion: trained tasks improve, untrained tasks do not.
The current consensus is that working memory capacity (the underlying chunk-controlled limit) is largely fixed in adulthood, but the strategies that surround it (chunking, rehearsal, attentional control, interference resolution) can improve with practice on a specific task. A chess player's working memory for chess positions improves as their chess expertise grows; their working memory for digit span does not. Working memory is not trainable in the muscular sense; what is trainable is the long-term-memory machinery that produces dense chunks within a specific domain.
The practical takeaway: do not buy a brain-training app expecting general cognitive gains. Do invest in domain expertise. The chunking density that comes with domain expertise is the part of the working memory equation you can actually move.
What This Means for Focus Work
Four implications for the way you organise focus time.
Offload aggressively. Working memory is the limiting reagent; do not waste it on things that can sit in a list. Inbox-zero, task lists, capture-everything systems exist because each external slot is a working-memory slot freed up for the actual work. Cal Newport's deep-work argument is partly an offloading argument: by removing competing tasks from working memory through ritual and environment, you free the entire bottleneck for one task.
Single-task. Multitasking is the working-memory pathology. Switching between tasks reloads the central executive every time and burns working memory on the switch cost. The Sophie Leroy attention-residue work (2009) showed that incomplete prior tasks continue to occupy working memory after the switch, which is why "just one quick check of email" is more expensive than it feels.
Chunk dense, not fast. When you encounter complex material, slow down enough to build the right chunks the first time. A poorly chunked encoding will eat working memory every time you revisit it; a well-chunked encoding will sit in long-term memory and free the workspace.
Use the phonological loop on purpose. If the task is verbal-heavy (writing, reading, problem-solving with internal monologue), avoid concurrent verbal noise (lyrical music, podcasts in the background, conversation). If the task is visuo-spatial (design, geometry, spatial reasoning), avoid concurrent visual clutter. Brown noise and instrumental music occupy the phonological loop with low-information acoustic signal that masks distractors without competing for verbal capacity, which is why they show up in the focus-music literature so often.
The ultradian rhythm piece has the temporal architecture of how working memory replenishes across the day. The hyperfocus piece covers what happens when working memory becomes locked on a single salient stimulus and the central executive loses its switching function.
The Bottom Line
Working memory is the four-slot bottleneck the brain runs every focus task through. The Baddeley model gives you the architecture: a central executive controlling a phonological loop, a visuo-spatial sketchpad, and an episodic buffer, with long-term memory underneath. The Cowan 4±1 capacity is the chunk-controlled real number. ADHD is, mechanically, a working memory disorder as much as an attention one. Working memory training does not transfer; domain expertise does. The interventions that move the needle are external scaffolding (lists, calendars, environmental cues), single-tasking (no switching), and modality-aware audio (the phonological loop occupied by signal that supports the task).
The pomodoro pattern is, partly, a working-memory protocol. Twenty-five minutes is short enough that the central executive does not need to switch within the block, long enough that the chunk being built can settle in long-term memory before the break clears the workspace. The audio inside the block does the phonological-loop occupancy job. The break clears decayed items so the next block starts fresh. Tomatoes is built around that pattern and is a one-time $39 with no subscription. The science is what the next two thousand words of any of the other pieces on this blog will tell you.